입력 : 2007.08.15 10:45
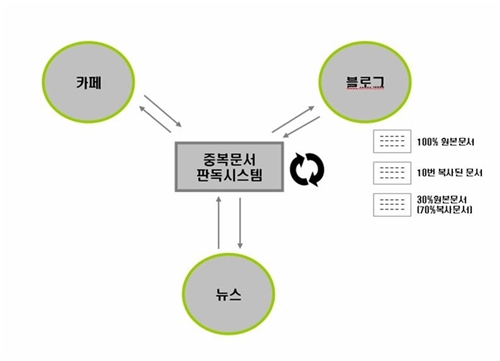
- ◇네이버 복사문서 판독시스템 구현 개요 / NHN 제공
- 네이버가 중복된 문서들을 판독해 검색 결과에 제외하는 기능을 지난달부터 가동한 가운데, 이를 구현하기 위한 ‘복사문서 판독시스템’의 원리를 소개하는 자료가 인터넷에 공개됐다.
NHN은 14일 오후 공식 블로그에 소개한 자료에서 네이버에서 지난달부터 적용하기 시작한 ‘복사문서 판독 시스템’에 대해 소개했다.
현재 네이버는 통합검색 블로그, 카페 검색결과에 중복결과를 제외할 것인지, 포함할 것인지 선택할 수 있는 메뉴를 제공하고 있다. 이렇게 되면 검색될 때 글을 처음 작성했던 사용자들의 블로그 글 원본이나 저작권이 있는 뉴스가 ‘퍼가기(스크랩)’만 한 다수의 일반 사용자들의 자료에 밀리는 문제점을 해결할 수 있게 된다. 원저작자의 권리를 보호해주고, 불펌 블로거들의 활동 영역도 어느 정도 보장해 주자는 취지다. 현재 네이버 통합검색의 기본 값은 ‘중복결과 제외’로 설정되어 있다.이를 제대로 구현하기 위해서는 해당 자료에 복제된 내용이 있는지 판독하는 여과장치가 정교해져야 한다. 네이버 관계자는 글에서 “게시물 간 복사 여부를 판단해 원본인 확률이 높은 게시물을 검색에 노출하는 방식”이라며 “2007년 초부터 판독 시스템을 새로 개발하기 시작했다”고 설명했다. 관계자는 “그 동안 네이버에서는 공들여 게시물을 생산한 원저작자의 권리를 검색에 적용하는 문제가 큰 고민이었다” 고 덧붙였다.
카페, 블로그, 언론사 뉴스 문서의 복사유무와 그 정도를 계산할 뿐만 아니라 단순 복제(Copy&Paste)한 문서까지도 파악해 통합 검색결과에서 제외함으로써 검색 서비스의 품질을 개선할 수 있다는 주장이다. 관계자는 “기존 시스템과 달리 하나의 문서를 의미 있는 단락단위로 나누어서 복사유무를 판독하기 때문에, 100% 똑같이 일치하는 문서뿐만 아니라 본문 일부가 중복되는 문서까지 알 수 있다는 점이 가장 큰 특징”이라고 손꼽았다.
여러 종류의 유사 문서가 동시에 존재할 때에는 게시물이 최초로 작성된 시간 등을 파악해 원본을 ‘추정’하는 방식을 사용했다, 관계자는 “중복문서 판독시스템은 원본을 100% 판독할 수 있는 시스템은 아니다”며 “다만 원본일 확률이 높은 문서를 추정하여 이를 검색에 보여주고 있는 것”이라고 설명했다.
만약 일반인들이 자신의 블로그에 뉴스를 스크랩하거나 상당량을 인용해 글을 작성한 경우는 어떻게 될까. 이런 경우 문서의 복사 정도를 계산해 그 정도가 ‘인용’의 수준을 넘어서는 경우(상당량을 그대로 복제한 경우)는 중복문서로 판단하게 된다. 네이버는 “뉴스의 경우에는 (원본 복제 보다는) ‘블로그/카페 담기’ 기능을, 블로그 카페의 경우는 ‘이 포스트를 내 블로그/카페에 담기’ 기능을 이용해 달라”고 당부하기도 했다.
한편 지난 2월 일반인들을 대상으로 진행된 ‘네이버 블로거 간담회’에서 이람 NHN 네이버 테마매니저는 “불펌 콘텐츠가 블로그 검색에 더 많이 노출된다는 지적을 많이 받았고, 잘 인식하고 있다”며 “펌글은 검색에서 제외하고 원본 글에 가중치는 부여하는 방안을 고민 중”이라고 말한 바 있다.
그는 특히 “블로그에는 ‘뉴스 펌’이 많은데, 유사도 비교를 통해 퍼간 글에 대한 뉴스 가중치를 부여하고, 뉴스 스크랩은 검색에서 배제하며, 원본 작성자가 상위에 랭크되는 패턴을 마련할 것”이라고 설명했었다.
'소금 > 세상사 이모저모' 카테고리의 다른 글
| 美軍 <지상_전투로봇> ...세계최초 실전(이라크) 배치 ... (0) | 2007.08.16 |
|---|---|
| 한국금융시장이 오히려 가장 큰 타격을 입었다. (0) | 2007.08.16 |
| 북한 주민 추정 시신 5구 발견- 동영상 뉴스 (0) | 2007.08.16 |
| 수시 입출금 통장(CMA) - 동영상 (0) | 2007.08.16 |
| ‘구글(google)’탄생이 구골(googol)’의 오타로 우연히 탄생한 신조어... (0) | 2007.08.15 |
댓글